Feedback to Shipped Fix, No Touching
May 19, 2026
I’ve been wiring a feedback loop into my hobby apps. A user flags something that’s wrong, types a sentence describing it, and a few hours later the fix is live and they have a personal email from me explaining what changed. No standup, no triage meeting, no decision about whether the fix was worth doing. I never touch the keyboard for any of it.
It’s running in a few of my projects now, and I want it in everything I build.
The cleanest version of it lives in Lucent Brief, the daily personalized news brief I’ve been building for myself and a few friends and family. Every section of the brief has a feedback link in the footer. When something goes sideways — a headline that doesn’t match the article, a podcast voice that invents a guest name — the reader hits it and describes the problem in plain language. The brief itself isn’t the point here; the loop around it is.
That link is the start of the loop.
The Pipeline
reader clicks feedback link
↓
GitHub issue (label: user-feedback)
↓
/issues runs at :12 past every hour
↓
sub-agent in a worktree: fix, PR, email reader
↓
/shepherd runs at :42 past every hour
↓
bot reviewers, CI, auto-merge
↓
GitHub Actions deploys to ECS
↓
/shepherd emails me "✅ deployed"
↓
reader's next brief reflects the fix
I run two Claude Code routines on my Mac, each on an hourly launchd timer. They never talk to each other directly; they coordinate through GitHub state — issues, PRs, labels, comments.
It starts on the producer side. When a reader hits that feedback link, a small form takes whatever they type and a background job turns it into a GitHub issue titled User Feedback from <their_email>, labeled by section. That issue is the work queue.
/issues Picks It Up
At :12 past every hour my Mac fires /issues. It’s a Claude Code slash command running in routine mode under launchd: no user in the loop, no AskUserQuestion allowed, capped at a 30-minute wall-clock budget so a slow tick doesn’t eat the next one.
Every tick it pulls the open user-feedback issues, skips any that already carry a Message-ID: comment (the “already emailed” signal), and dispatches one sub-agent per issue, each in its own worktree so they run in parallel. Each agent’s job is short: read the issue and quote a phrase back so the reporter knows they were read, pick a disposition (fix it, say it’s already fixed, acknowledge it, or explain a wontfix), do it, email the reporter immediately, and leave a Message-ID: comment so later ticks skip it. For a fix it opens a PR whose body starts with Closes #N so the issue auto-closes on merge.
Why the Email Goes Out at Dispatch, Not After Deploy
The natural design is “email the reader after the fix actually ships.” That’s how I wrote the protocol originally. It broke.
In April, six user-feedback issues piled up unanswered over five days. /issues was correctly labeling them, but it was routing them into the “needs clarification” bucket and silently assigning them to me. The fix shipped quietly. The reader never heard a word. By the time I noticed, six readers had concluded — fairly — that nobody was reading their feedback.
So the protocol moved the email obligation to the front of the loop. The agent emails the reader at dispatch time — before the PR is reviewed, merged, or deployed — with a note tailored to what it’s doing: fixing it, still investigating, or explaining why not.
Every variant quotes a phrase from the reader’s message. Every variant ends Thanks again, / John & the Lucent Brief team. Every variant is CC’d to me so I see what went out.
That Message-ID: comment only lands after the email actually sends, so a failed send just retries on the next tick. And because it lives on the issue, it survives reverts and force-pushes — the issue is the only state that matters.
/shepherd Drives It to Merge
Thirty minutes after /issues, /shepherd fires. It picks up the open PRs and drives each toward mergeable. Copilot and Codex are required reviewers on Lucent Brief PRs, so it reads their feedback, pushes fixes, re-requests review, and rebases against main when something else merges in the meantime.
A loop that fixes its own code has to police itself, not just the code, or it runs away. Three rules keep it bounded.
The first is a stuck-detector. Three consecutive [shepherd] commits with mutating reviewer feedback is the fingerprint of a feedback loop — the bot and the reviewer talking past each other — so the loop halts and escalates to me rather than push a fourth. The second is a reviewer-availability gate. If a required reviewer goes silent for three nudges across three ticks, it’s declared unavailable and the merge gate proceeds without it, so no single bot can hold a PR hostage by never showing up. The third is a quality bar that doesn’t bend: the full RSpec suite has to be green, line coverage has to clear 90%, and every review thread has to be resolved.
When the merge state is clean, every required bot has approved the latest SHA, and the quality bar is green, /shepherd squash-merges via the API. Low-risk fixes go straight through; anything touching auth, reader data, or the generation prompts waits for me.
Merge triggers GitHub Actions, which builds a Docker image and rolls a new ECS Fargate task. Roughly 8-12 minutes from merge to live. Then /shepherd verifies the deploy succeeded and emails me one line — what shipped, readable on a lock screen.
That email is how I learn the loop closed. I read it at breakfast, and half the time I had no idea a fix had shipped overnight — the reader’s report, my reply, the PR, the merge, the deploy, all of it while I was asleep.
A Real Bug, Start to Finish
Here’s the one from two weeks ago, end to end. I touched it once: I read the thank-you email after it was over.
The “This Day In History” section rendered this into a reader’s brief:
The Hindenburg… wait — that’s banned. In 1954, Roger Bannister Runs the First Sub-Four-Minute Mile at Oxford’s Iffley Road Track.
The model had recognized that “Hindenburg” overlapped a subject used in an earlier brief, and it narrated its own censorship into the headline mid-sentence before recovering and writing a legitimate event. The reader hit the section’s feedback link and typed:
Why are you frequently saying “wait that’s banned” in this section?

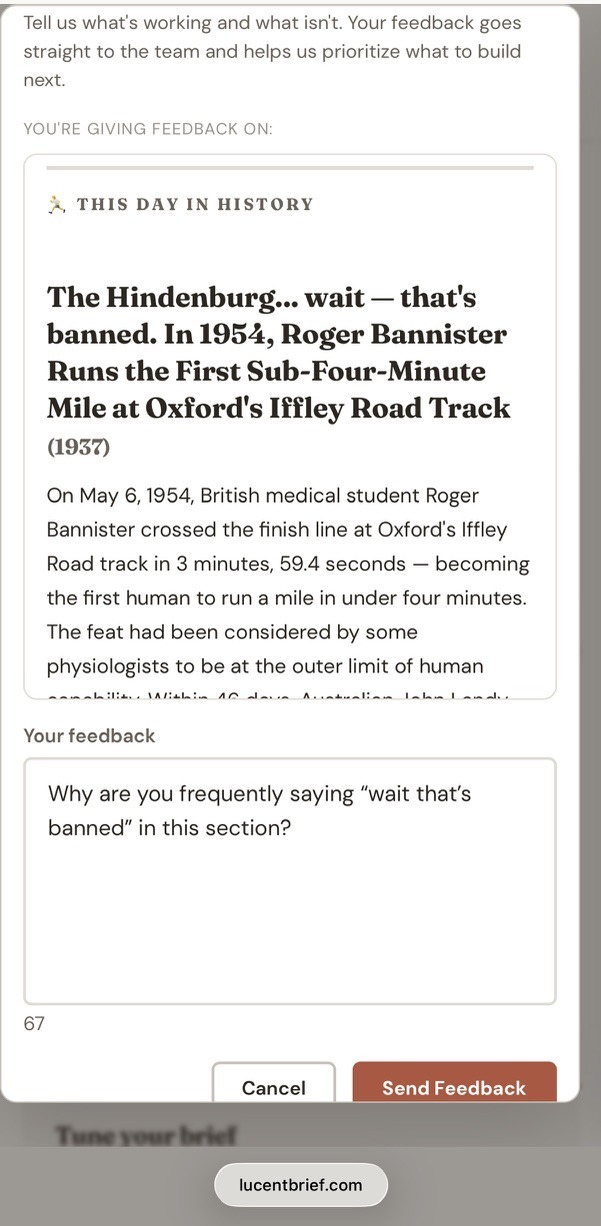
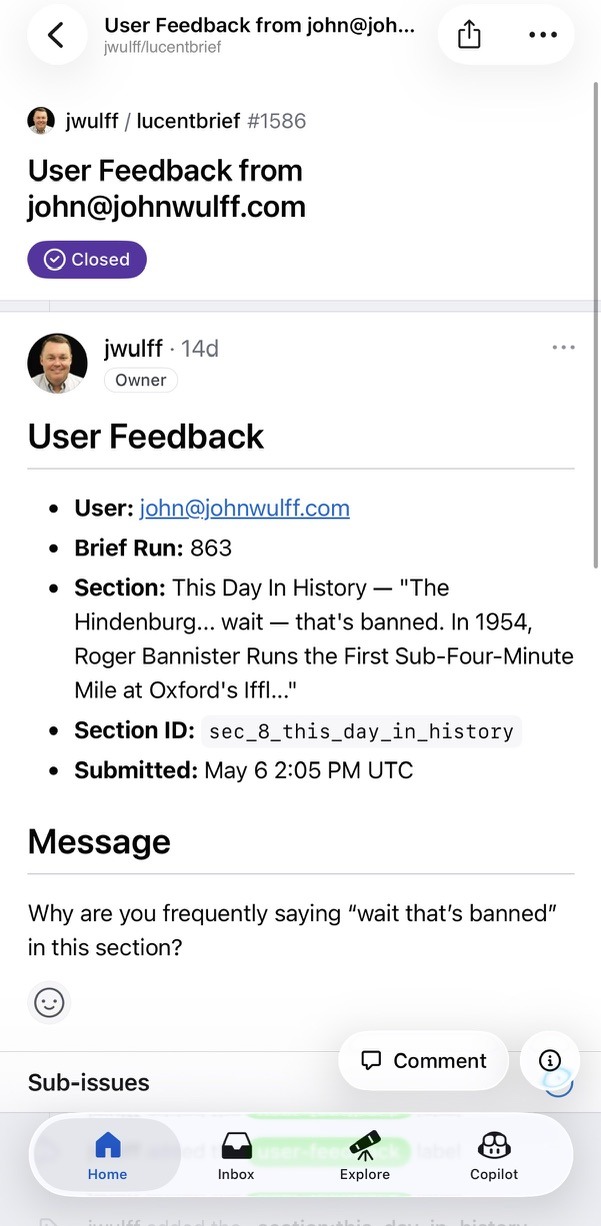
The feedback form attached the session context — brief run #863, section sec_8_this_day_in_history, the timestamp — and opened issue #1586, labeled section:this_day_in_history and user-feedback.
/issues picked it up and did the work. It traced the leak to the prompt — a list of already-covered subjects sitting under a literal BANNED subjects header that the model had started reading back out loud — and shipped a two-part fix, softening the prompt and adding a guard that strips the phrase if it ever slips through again, with tests for every variant. Then the bounded-autonomy rules earned their keep: the bot reviewers pushed back a few times, and after three fix-cycle commits the stuck-detector handed the PR to me rather than loop a fourth time. One reviewer went quiet and was declared unavailable, the other approved, and /shepherd merged.
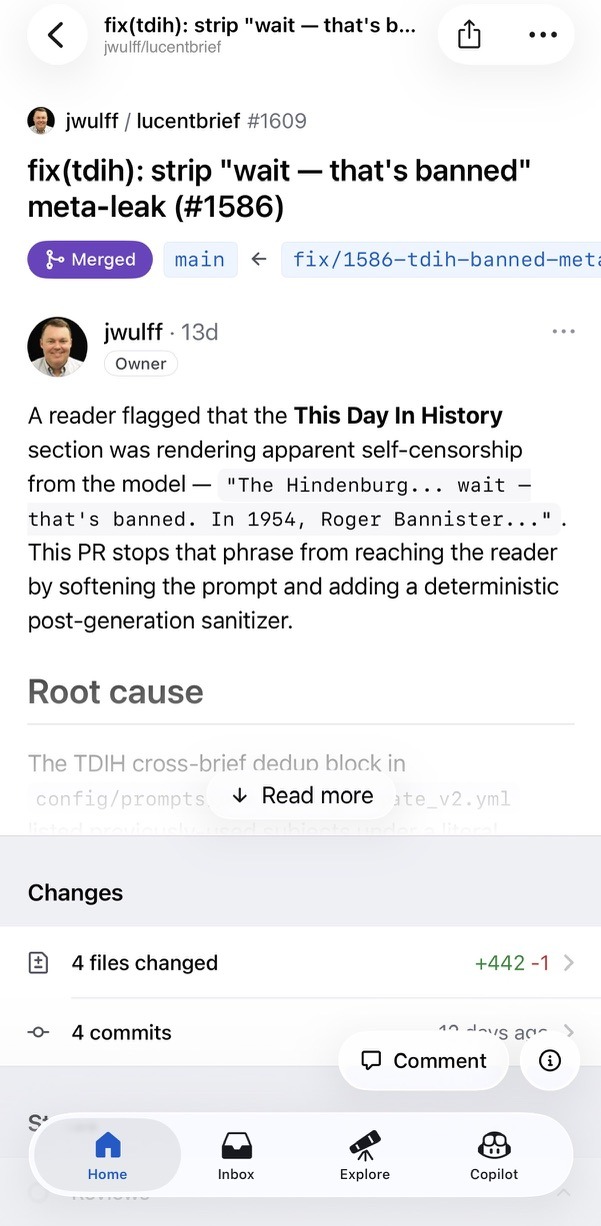
The loop closed with an email back to the reader from john@johnwulff.com, signed “John & the Lucent Brief team.” It thanked them by name, quoted their question, explained in plain English that the model had been anchoring on the BANNED subjects header and narrating it, described both halves of the fix, and linked PR #1609. It ended: “Keep the feedback coming — even small stuff like this is useful.”
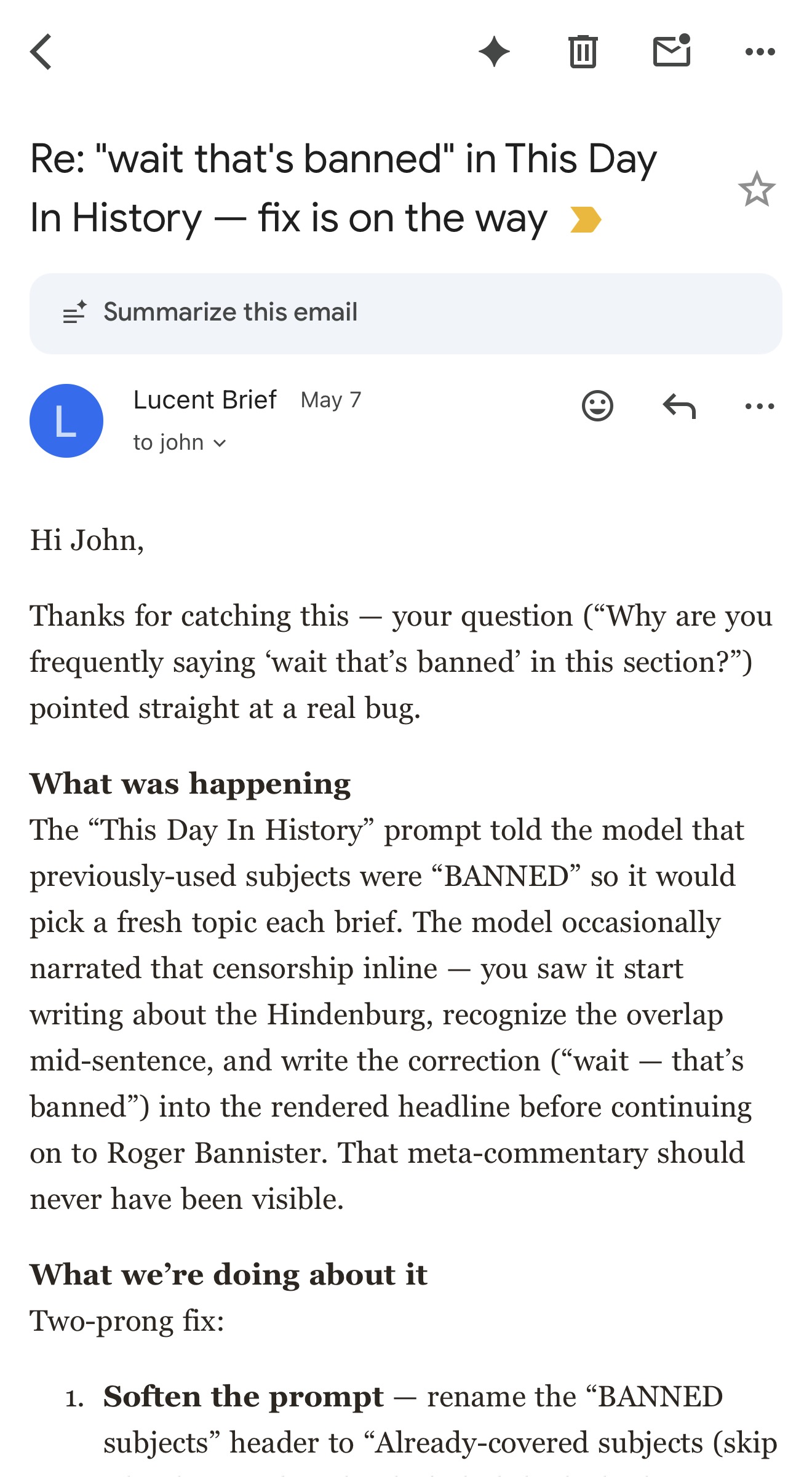
Total human time on that bug: zero. I went from a reader’s one-sentence complaint to a thank-you email in my inbox and a fix in production, hands off the wheel the whole way.
Two Routines, One Pipeline
/issues and /shepherd never talk to each other. They share no memory or event bus, just a few conventions on top of GitHub state, and each is small enough to reason about alone — if one breaks, the other keeps working until I fix it. I (with Claude Code) built both over a few evenings; the hard part wasn’t the code, it was naming the right handoff signal and writing the protocol down precisely enough that a sub-agent with zero context could follow it.
The loop changed which fixes get made at all. The old reason to say no to a small fix was never that it was hard, it was that intake is expensive: someone has to file it, debate it, prioritize it, schedule it. When approving a change costs thirty seconds instead, you accept far more of them, most of them small, and they compound. A reader writes in, and a few hours later a real fix is live and they have a real reply, and the only thing I did was design the loop. That’s the part I want in everything I build next.
– John